
Knowledge bases for Amazon Bedrock の Chat with your document を試してみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは! AWS 事業本部コンサルティング部のたかくに(@takakuni_)です。
少し前のアップデートですが、Knowledge bases for Amazon Bedrock で Chat with your document 機能がリリースされました。
この機能を使うことで、単一のドキュメントにおける RAG の回答であれば、ナレッジベースを構築しなくても、自然言語でドキュメントに対する質問を返答できるようになりました。詳しいことは興味のある方向けに記載しますが、従来提供されているナレッジベースとは異なる仕組みで RAG を行うため、ナレッジベースとしての性能評価にはお勧めしません。
前置き
本エントリでは、少しややこしいですが以下の表現をします。
- Knowledge bases for Amazon Bedrock
- Amazon Bedrock の中の 1 つの機能を指す
- ナレッジベース
- Knowledge bases for Amazon Bedrock の中の 1 つの機能、構成要素としてのまとまりを指す
- Chat with your doument
- Knowledge bases for Amazon Bedrock の中の 1 つの機能、ナレッジベースとは別機能を指す
現状把握
今まで Knowledge bases for Amazon Bedrock で利用して、 RAG のシステムを構築するには以下のような、ナレッジベースの構築が不可欠でした。
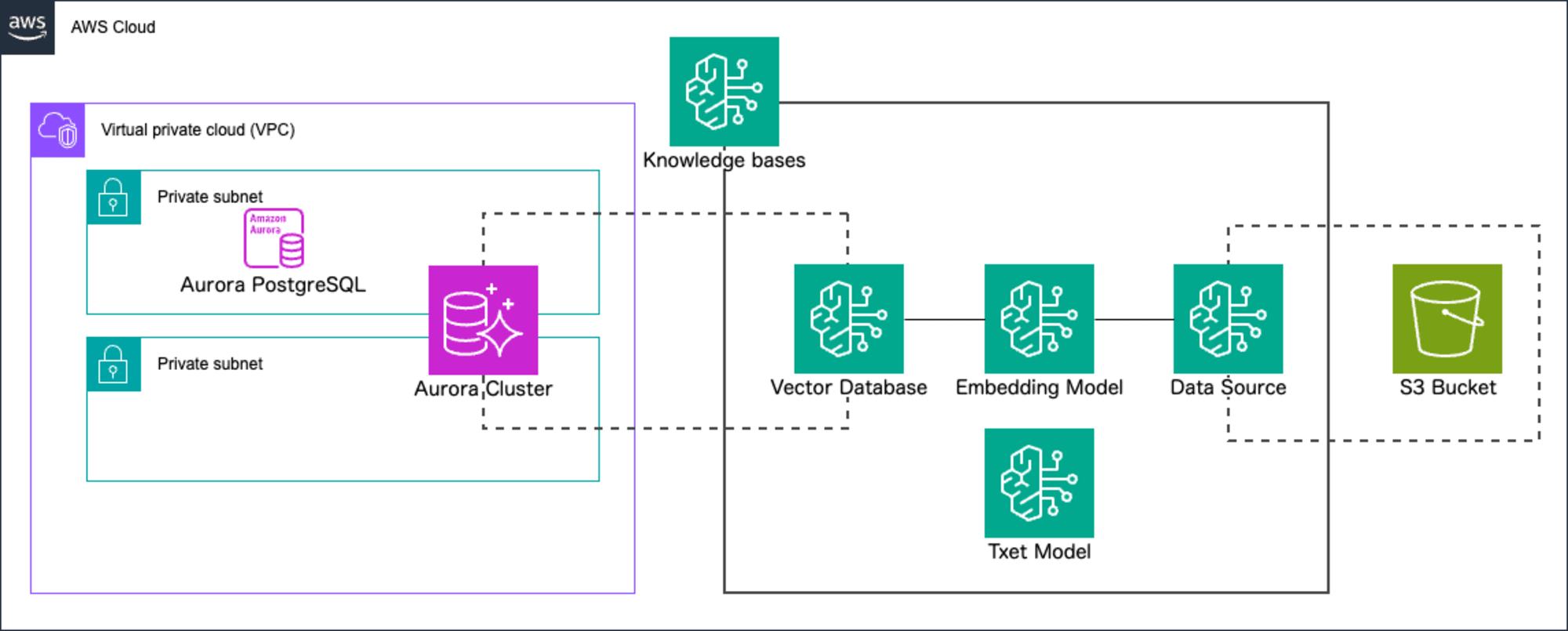
これからは、質問する対象が 1 ファイルの場合、 Chat with your doument 機能を使って自然言語でドキュメントに対する質問ができるようになりました。 AWS Blog でもベクトルデータベースやストレージの管理について言及されていますね。
In the end, you would pay more for the vector database storage and management than for the actual FM usage.
2024/05/10 時点でサポートしているリージョンは次のとおりです。
- バージニア北部
- オレゴン
- シドニー
また、現状利用可能なモデルは Claude 3 Sonnet のみとなっています。
制約事項
その他、制約事項を押さえます。
- ファイルの種類
- md
- txt
- doc
- docx
- html
- csv
- xls
- xlsx
- ファイルのサイズ
- 10 MB 未満
File types: PDF, MD, TXT, DOC, DOCX, HTML, CSV, XLS, XLSX. There is a preset fixed token limit when using a file under 10MB.
Chat with your document data using the knowledge base - Amazon Bedrock
トークン制限
その他、トークン数に制限があります。
インプットトークン
単一のファイルサイズが 10 MB 未満だったとしても、内容がテキスト中心だった場合、トークンの制限に抵触する可能性があります。
A text-heavy file that is smaller than 10MB can potentially be larger than the token limit.
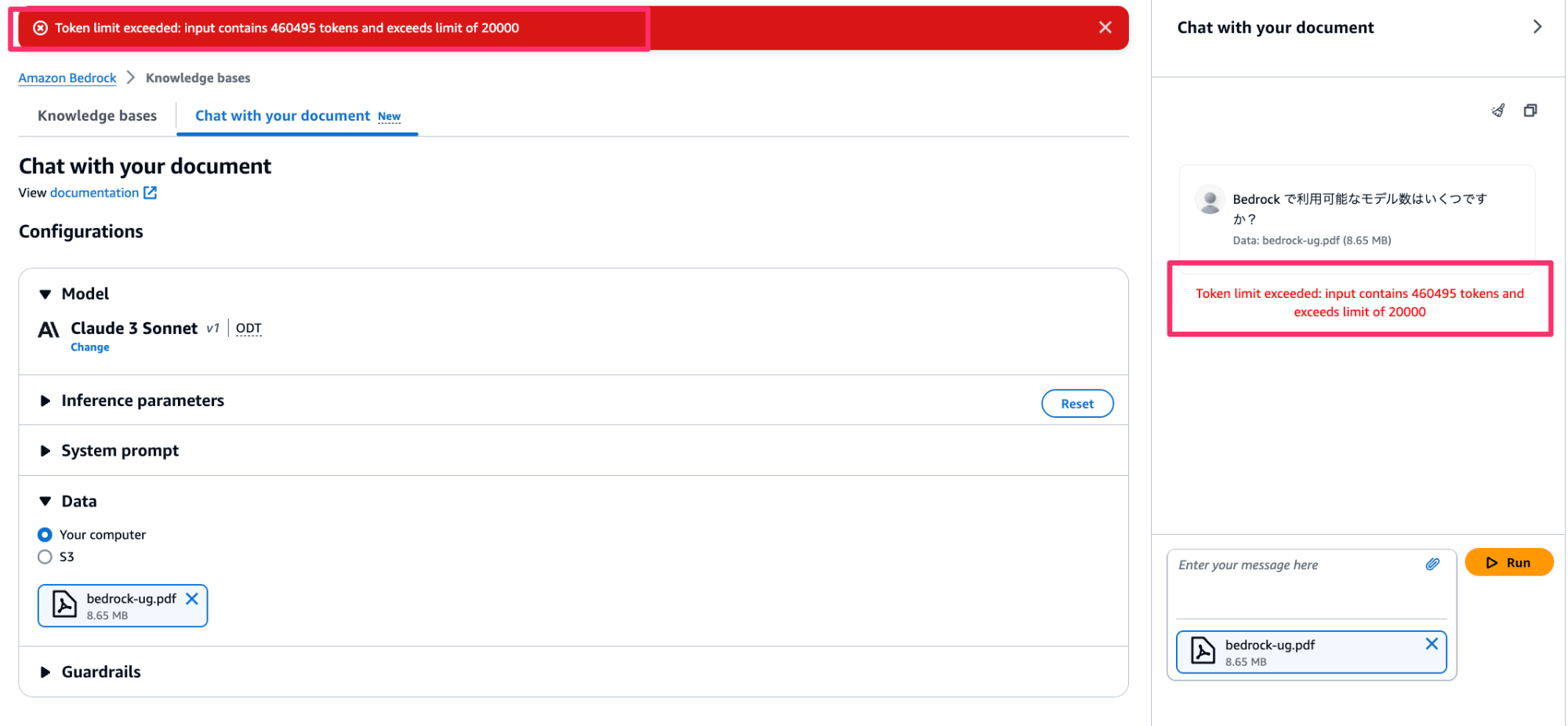
現状確認できるトークンリミットは 20,000 となっていました。(今後の機能拡張によって、モデルごとにトークンリミットが設けられる仕様なのではないかと推測しています)
データの永続性
使用後にドキュメントやデータを保存しない点が明記されてて嬉しいですね。
Chat with your document does not store your document or its data after use.
Chat with your document data using the knowledge base - Amazon Bedrock
やってみる
マネジメントコンソール
それでは、実際にやってみます。Bedrock コンソールよりナレッジベース、 Chat with your doument をクリックします。

モデルの選択を行います。現在は Claude 3 Sonnet のみサポートしているため、そのまま適用します。

データはローカル(Your computer)または、S3 を選択できます。今回はローカルからアップロードしてみます。

ファイルのアップロード後、質問してみると回答が返ってきていますね。

AWS SDK
AWS SDK (boto3) からもやってみます。以下のコードを利用して S3 経由で Chat with your document 機能を試してみます。
import boto3
bedrock_client = boto3.client(
service_name="bedrock-agent-runtime", region_name="us-east-1"
)
model_id = "anthropic.claude-3-sonnet-20240229-v1:0" # Replace with your model ID
document_uri = "s3://XXXXXXXXX/tempura.md" # Replace with your S3 URI
def retrieveAndGenerate(
input_text, source_type, model_id, document_s3_uri=None, data=None
):
region = "us-east-1"
model_arn = f"arn:aws:bedrock:{region}::foundation-model/{model_id}"
if source_type == "S3":
return bedrock_client.retrieve_and_generate(
input={"text": input_text},
retrieveAndGenerateConfiguration={
"type": "EXTERNAL_SOURCES",
"externalSourcesConfiguration": {
"modelArn": model_arn,
"sources": [
{
"sourceType": source_type,
"s3Location": {"uri": document_s3_uri},
}
],
},
},
)
else:
return bedrock_client.retrieve_and_generate(
input={"text": input_text},
retrieveAndGenerateConfiguration={
"type": "EXTERNAL_SOURCES",
"externalSourcesConfiguration": {
"modelArn": model_arn,
"sources": [
{
"sourceType": source_type,
"byteContent": {
"identifier": "testFile.txt",
"contentType": "text/plain",
"data": data,
},
}
],
},
},
)
response = retrieveAndGenerate(
input_text="タコの天ぷらを作るときのコツは何ですか?",
source_type="S3",
model_id=model_id,
document_s3_uri=document_uri,
)
print(response["output"]["text"])
実行結果が綺麗に返ってきました。
takakuni@ % python app.py
タコの天ぷらを作るときのコツは、次の点に注意することです:
1. タコは硬いので、包丁で切る前に表面に格子状の切り込みを入れると柔らかく仕上がります。
2. タコの頭は苦みがあるので、しっかりと取り除きましょう。
3. タコは火が通りにくいので、揚げ時間は長めに設定することが大切です。
まとめ
以上、「Knowledge bases for Amazon Bedrock で Chat with your document 機能がリリースされました。」でした。単一のドキュメントのみであれば、スピーディーに RAG を体験できるいい機能だと思います。使い方によってはかなり便利な機能だと思うので、ぜひ活用してください。
補足
さて、興味のある方向けの補足情報です。冒頭でも説明しましたが、ナレッジベースと Chat with your document の機能の違いについてご紹介していきます。
Chat with your document にインプットするドキュメントは以下のような簡素なもので説明します。
- 名前:たかくに
- 部署:AWS 事業本部コンサルティング部
- 肩書:ソリューションアーキテクト
- 所属:札幌
エンべディングは行わない
Chat with your document では、エンべディングは行いません。(つまり、チャンキングも行いません。)
そのため、対象のドキュメントをそのままテキストモデルへインプットとして提供します。デフォルトで以下のプロンプトが利用されます。
You are a question answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.
Here are the search results in numbered order:
$search_results$
$output_format_instructions$
このプロンプトとアップロードしたドキュメントを利用して、最終的なプロンプトを作成します。
次の内容が実際にテキストモデルに対して実行されたログの例です。content で囲われている部分にドキュメントの本文が突っ込まれていることがわかりますね。テキスト生成モデルの力で RAG が全て完結していることがわかります。
{
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0",
"timestamp": "2024-05-11T02:52:30Z",
"accountId": "XXXXXXXXXXXX",
"identity": {
"arn": "arn:aws:sts::XXXXXXXXXXXX:assumed-role/cm-takakuni.shinnosuke/cm-takakuni.shinnosuke"
},
"region": "us-east-1",
"requestId": "32573bc7-e44b-4059-b0c3-7e211537f329",
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"anthropic_version": "bedrock-2023-05-31",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "たかくにはどのオフィス所属ですか?"
}
]
}
],
"system": "You are a question answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.\n\nHere are the search results in numbered order:\n<search_results>\n<search_result>\n<content>\n- 名前:たかくに - 部署:AWS 事業本部コンサルティング部 - 肩書:ソリューションアーキテクト - 所属:札幌\n</content>\n<source>\n1\n</source>\n</search_result>\n\n</search_results>\n\nIf you reference information from a search result within your answer, you must include a citation to source where the information was found. Each result has a corresponding source ID that you should reference.\n\nNote that <sources> may contain multiple <source> if you include information from multiple results in your answer.\n\nDo NOT directly quote the <search_results> in your answer. Your job is to answer the user's question as concisely as possible.\n\nYou must output your answer in the following format. Pay attention and follow the formatting and spacing exactly:\n<answer>\n<answer_part>\n<text>\nfirst answer text\n</text>\n<sources>\n<source>source ID</source>\n</sources>\n</answer_part>\n<answer_part>\n<text>\nsecond answer text\n</text>\n<sources>\n<source>source ID</source>\n</sources>\n</answer_part>\n</answer>",
"max_tokens": 2048,
"temperature": 0,
"top_p": 1,
"stop_sequences": ["\nObservation"],
"top_k": 50
},
"inputTokenCount": 436
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"id": "msg_01LFbpS85K1AWAEACdKoXbJM",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "<answer>\n<answer_part>\n<text>\nたかくにの所属オフィスは札幌です。\n</text>\n<sources>\n<source>1</source>\n</sources>\n</answer_part>\n</answer>"
}
],
"model": "claude-3-sonnet-28k-20240229",
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 436,
"output_tokens": 64
}
},
"outputTokenCount": 64
}
}
利用可能なモデル
現状、Chat with your document の場合、サポートしているテキスト生成モデルは Claude 3 Sonnet のみになります。ナレッジベースだと、 RetrieveAndGenerate API を利用して、 Claude 3 Sonnet 以外のモデルも利用できます。(Retrieve API であれば、さらに多くのモデルをサポートします。)
ちなみに Chat with your document で、 Claude3 Haiku を SDK 経由で指定した場合、以下のようなエラーになります。
takakuni % python app.py
Traceback (most recent call last):
File "/Users/takakuni/Desktop/genai-blog/knowledge_bases_chat_with_your_document/app.py", line 56, in <module>
response = retrieveAndGenerate(
^^^^^^^^^^^^^^^^^^^^
File "/Users/takakuni/Desktop/genai-blog/knowledge_bases_chat_with_your_document/app.py", line 18, in retrieveAndGenerate
return bedrock_client.retrieve_and_generate(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/takakuni/Desktop/genai-blog/knowledge_bases_chat_with_your_document/app.py/.venv/lib/python3.12/site-packages/botocore/client.py", line 565, in _api_call
return self._make_api_call(operation_name, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/takakuni/Desktop/genai-blog/knowledge_bases_chat_with_your_document/app.py/.venv/lib/python3.12/site-packages/botocore/client.py", line 1021, in _make_api_call
raise error_class(parsed_response, operation_name)
botocore.errorfactory.ValidationException: An error occurred (ValidationException) when calling the RetrieveAndGenerate operation: The provided model is not supported for EXTERNAL_SOURCES RetrieveAndGenerateType. Update the model arn then retry your request.
お手軽感とのバランス
とはいえ、 Chat with your document はとても気軽に RAG の仕組みを利用できる素晴らしい機能です。制約事項がいくつかありますがハマれば管理コストがほとんどない機能です。
今後の機能拡張に期待ですね。 AWS 事業本部コンサルティング部のたかくに(@takakuni_) でした!









